Blog
Git vs SVN
There are so many comparisons of Git vs SVN outside, but as far as I can tell, 99% of them are biased. (And so is this one, probably.)
And there are many Git tutorials outside, and none is clear enough so others could get on hand easily. In fact, it remains to be one of the major drawbacks of Git.
I have used SVN for many years, and used Git for quite a while now. I admit that I am not yet an expert of Git, but I have tried and suffered a number of traps of Git, and I learned a lot from those painful experiences. Some of the traps could get me stuck for one day.
Difference between Git and SVN
First of all, what’s the most hardcore difference between these two? Undoubtedly, these two version control systems are in fact totally different. But they could also do some similar things, e.g. branching, tagging, external linking. The git-scm.com mentioned that the major difference is how they store the things (stored snapshots instead of deltas). But I think . The storage could help the performance of checkout, branching, and rebase, but it did not reflect the fundamental difference in behavior.
In my opinion, there are two core differences:
A. Git has a powerful and complete local repository
B. Git provides built-in support of branch
A Full Blown Local Repository
The followings diagram show the core difference:
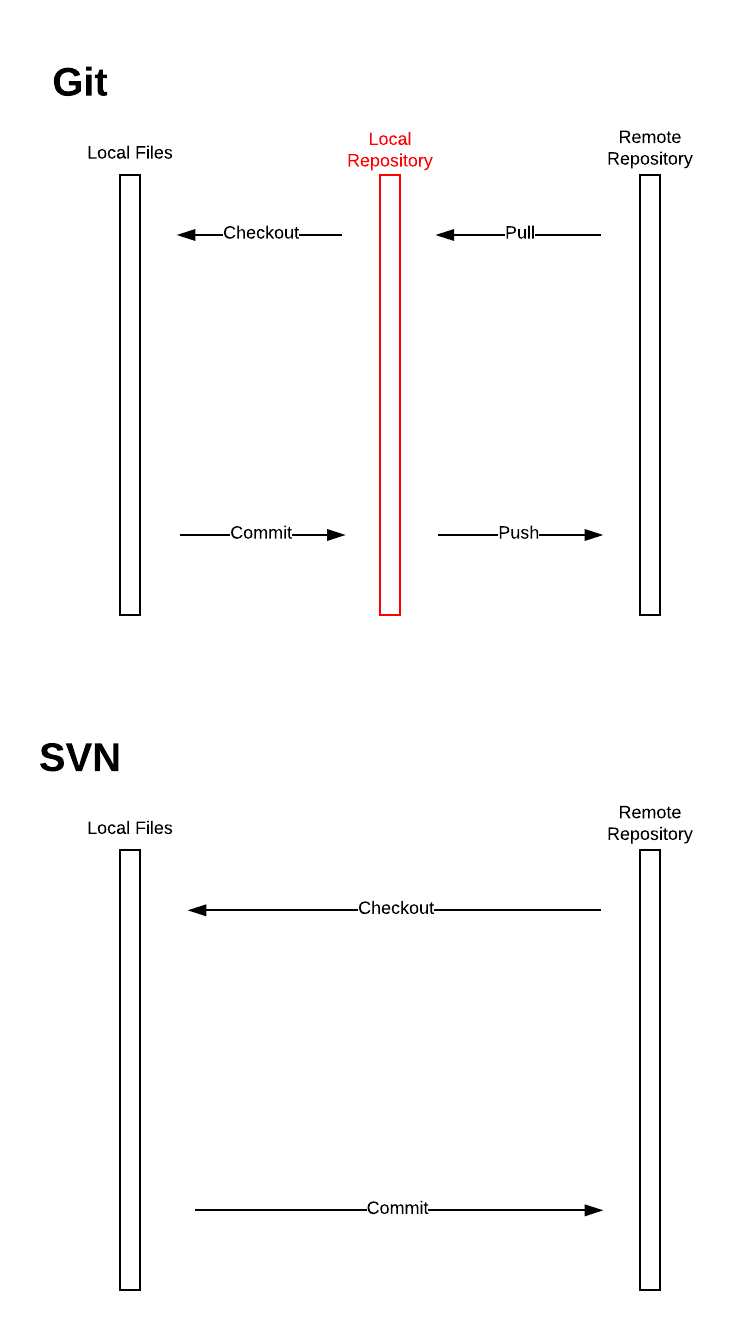
I hide the staging area here, because the concept of staging area exists for both SVN and GIT. It’s an important concept, but and it’s NOT an important difference between Git and SVN.
Most of the operations of GIT are available offline. Despite the checkout and commit, one could also do the merge, cherry-pick, rebase and branching without the network access. The network is only required for the sync up process between the local Git repository and remote ones.
On the contrary, SVN needs the network for most operations. One could still add, delete and edit local files, but if they want to register any changes into the repository, then the network access is mandatory because there is no such thing as a local repository in SVN.
One may regard Git as a special kind of SVN set up. The user has set up two repositories in total. One is file-based repository (e.g. file:///svn/repo1) and the other is network based (http://svn.example.com/repo1). And there are magic interactions between the file-based repository and network repository. The following diagram illustrates an example:
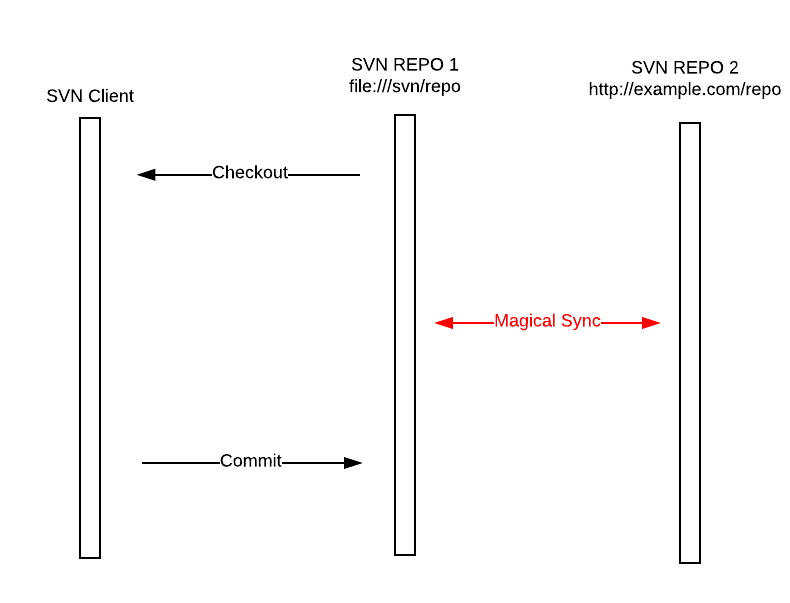
However, such SVN set up is just impossible in reality. There is no such powerful and flexible sync process in SVN. There is a command called ‘svnsync’, but it only provides a very limited capability of synchronization. After all, SVN is aimed for a central repository, instead of multiple distributed repositories.
Such difference has ONE obvious pro and con, respectively, for Git:
Pro: Git users could have the version control even without the network, e.g. when you need to do the coding on the plane, in the train, or at the restaurant without network access.
The cut of dependency of network also means super fast operations, e.g. create a local branch in Git would take only a split of seconds.
Branch creation on SVN side is actually fast too, but the network overhead makes it impossible to be finished within 1 second.
Con: If the developer accidentally removed the source folder (include the .git folder), formatted the drive, or have virus infected the machine. You may think it’s rare to happen, but if the project involve 10+ developers, and everyone push the changes once a week, and the project goes on for 1 year, then the probability may be bigger than you thought. If the developer is junior and not familiar with Git, he could easily lose the changes via wrong commands.
For SVN, all changes are always protected by the central repository, so unless the repository server is down, your code would always be safe (up to the last timestamp of commit). Yes, the same manual mistakes also apply to SVN developers, but with simpler command and higher commit frequency the side impact of code lost is much smaller.
Of course, the GIT users could also do the push automatically for every commit , but that would just defeat the purpose of using Git.
Built-in support of branches
Another major difference is the built-in support of branches in Git. SVN could have branches too, but it’s a practice and workflow, not inside the command argument and DNA.
Git encourages developers to use branches, each developer should set up his own branch, work on it, fully test it, and pack it into one commit/changeset and apply to the main trunk. Some developers even set up a branch for just one bug fix, or one trial attempt.
That approach has strong historical reasons. Git was initially developed by Linus Travolds for kernel development. In each kernel developer is supposed to strong enough to stand on its own, do all the unit tests, and all the gate keeper need to do is to review the patch and merge it. The manager would not care about how you work it out, they only care about the end feature 1 month later. So convenient and local based branching is critical for those kernel developers (as well as most other open source developers).
For SVN, everything is linear, whenever you add / delete / edit any file, the revision number just increment by one. Even if you try to rollback some changes, it’s also regarded as a new changeset and increment the version number.
For Git, however, there are two dimensions, one is branch and the other is revision. Each version is a point inside the space, so a linear revision number obvious will not work. Moreover, different developers may try to create different spots (revisions) in their own version-branch space, some of those spots would be kept in local machine forever, and some others would be used to sync with up remote repositories. So Git has no choice, but used a hash number (SHA-1) for the revision number.
The following diagram illustrate the scenario:
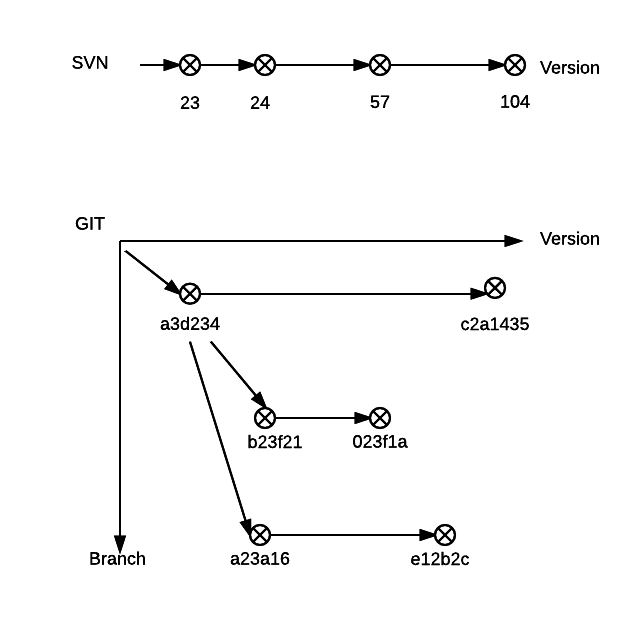
This also brings to major pros and cons:
Pros: – Two-dimensional traversal is easy, no conflict would be made. That makes branching, cherry pick and rebase is super easy. – As mentioned before branching the core of the whole philosophy of Git.
Cons: – Since branching is explicitly aimed at that project, one repository could only host one project (because there is only one intersection between the two dimensions). – For SVN, the branch is just another path in URL, it’s like any other source code folder, except you would use it for the branching purpose. So one repository could contain any number of projects, sub-projects, and branches. In fact, SVN encourages using one repository for all projects. – Another apparent con for me is the pronunciation of hash, you can read it out as easy as numbers. It brought some overhead when you try to communicate with the people near your table. You can’t shout out the version number easily. – Another consequence of two-dimensional space is, it allows you freely traverse in the space and kill nodes in the middle. In Git, it’s common to delete some branches after experiments. For sane and experienced developers it’s not a problem. But for some junior and unpredictable engineers (I met a lot), that could be an issue.
Conclusion
Git and SVN are just totally different. They are fundamentally different from design.
Git is super good for open source development, everyone is supposed to be good enough to accomplish his tasks.
But for consulting companies where a central management and safety is first place, I doubt that it’s the best choice.
References
http://blog.podrezo.com/git-introduction-for-cvssvntfs-users/
https://git-scm.com/book/en/v2/Getting-Started-Git-Basics
http://rogerdudler.github.io/git-guide/
http://svnbook.red-bean.com/en/1.7/svn.branchmerge.using.html